














Despite the success in large-scale text-to-image generation and text-conditioned image editing, existing methods still struggle to produce consistent generation and editing results. For example, generation approaches usually fail to synthesize multiple images of the same objects/character but with different views or poses. Meanwhile, existing editing methods either fail to achieve effective complex non-rigid editing while maintaining the overall textures and identity, or require time-consuming fine-tuning to capture the image-specific appearance. In this paper, we develop MasaCtrl, a tuning-free method to achieve consistent image generation and complex non-rigid image editing simultaneously. Specifically, MasaCtrl converts existing self-attention in diffusion models into mutual self-attention, so that it can query correlated local contents and textures from source images for consistency. To further alleviate the query confusion between foreground and background, we propose a masked-guided mutual self-attention strategy, where the mask can be easily extracted from the cross-attention maps. Extensive experiments show that the proposed MasaCtrl can produce impressive results in both consistent image generation and complex non-rigid real image editing.
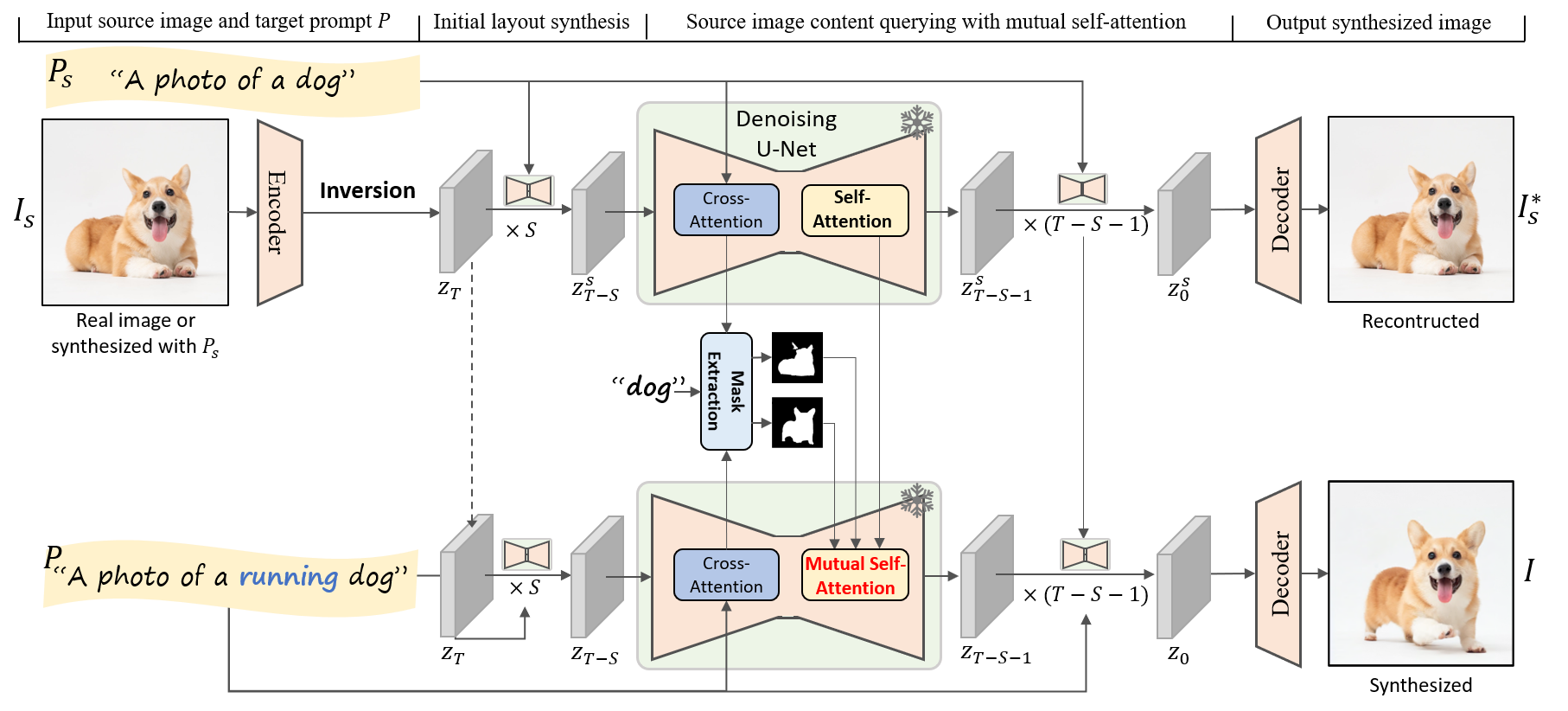
Pipeline of the proposed MasaCtrl. Our method tries to perform complex non-rigid image editing and synthesize content-consistent images. The source image is either real or synthesized with source text prompt Ps. During the denoising process for image synthesis, we convert the self-attention into mutual self-attention to query image contents from source image, so that we can synthesize content-consist images under the modified target prompt P.

Consistent synthesis results of different methods on the synthetic images. From left to right: the source image text description, generated source image, editing phrase, our results, P2P [2], SDEdit [3], and PnP [4].

Real image editing results of different editing methods on real images. From left to right: the source real image, our results, P2P [2], SDEdit [3], and PnP [4].

Consistent synthesis results (left part, with sketch guidance) and real image editing results (right part, with canny guidance) with MasaCtrl integrated into T2I-Adapter [1].

Consistent synthesis results of MasaCtrl with Anything-V4 checkpoint.

With dense consistent guidance, MasaCtrl enables video synthesis without fine-tuning. Please refer to the carousel to see the video synthesis results.
[1] Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
[2] Prompt-to-Prompt Image Editing with Cross-Attention Control
[3] SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
[4] Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
@InProceedings{Cao_2023_ICCV,
author = {Cao, Mingdeng and Wang, Xintao and Qi, Zhongang and Shan, Ying and Qie, Xiaohu and Zheng, Yinqiang},
title = {MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {22560-22570}
}